why has GPT-4’s accuracy been declining so much!?
Understanding why GPT's accuracy has been declining and what this means for the future of LLMs.
Read MoreComputer Science Student @ University of Toronto

Hey, I'm Dev Shah and I'm a 21 year old Machine Learning researcher based in Toronto. I’m currently a ML researcher working at Vector Institute under Dr. Bo Wang; working on building the best biological foundation models for drug discovery. I’m also studying Computer Science at the University of Toronto. My ultimate aspiration is to make a significant and lasting positive impact on the world, with the hope of touching the lives of billions. While I acknowledge that achieving this goal may be a long and challenging journey, it is one that I am wholeheartedly committed to pursuing. Check out my portfolio and skills below! I will be posting updates on my website and throughout my newsletters, make sure to subscribe below! Stay tuned :)
Shopify
Worked on pretraining and finetuning generative recommender models to elevate the merchant experience on Shopify. Designed experiments to evaluate model performance and improve recommendation quality.
Vector Institute
Worked in Dr. Bo Wang’s lab on a cutting-edge research project to develop the best foundational model for biology and DNA sequence modeling. Led large-scale experiments investigating scaling laws.
Immigration, Refugees and Citizenship Canada
Engineered and deployed ML models for text classification, leveraging NLP techniques to optimize email categorization. Utilized AWS and Amazon SageMaker for model training and deployment.
Fallyx
Developed a Machine Learning pipeline for fall detection. Using a CNN model to classify falls using 6-axis sensor data and engineered a hybrid Conv1D-LSTM model for time series analysis.
University of Toronto Missisauga
Developed a PointNet Deep Learning model which was used for age classification of human pelvic bones. Worked with 3D data and performed pre-processing techniques to enhance the model's robustness and accuracy.
Robot Vision & Learning Lab
Assisted in developing a digital twin of a chemistry lab to improve efficiency and safety outcomes. Worked with NVIDIA's Omniverse platform to create body assets and robotics equipment in a simulated virtual environment.
Interactions LLC
Created a LLM driven avatar using NVIDIA's Omniverse platform and Audio2Face interface for enhancing customer service. Leveraged a tech stack including Python, PyTorch, AWS EC2, Docker, GRPC, and Hugging Face.
University of Toronto
Developing machine learning models using contrastive learning for feature extraction and diagnosis of knee ultrasounds using advanced algorithms such as the Gaussian Pyramid and Encoder models.
Interac Corp.
Conducted a comprehensive and in-depth market analysis, employing robust research methodologies to examine emerging trends and technologies that bear direct implications on the trajectory of financial services.
University of Toronto
Studying Data Analysis, Software Development, Machine Learning, Deep Learning, Object-Oriented Programming, Operating Systems, Mathematics, Data Structures & Algorithms.
Ability to analyze and interpret complex data
Proficient in developing software using various programming languages and tools
Strong understanding of object-oriented programming concepts and design patterns
Strong mathematical skills including calculus, linear algebra, and statistics
Python, Java, Swift, JavaScript, C, C++, Assembly, TypeScript, SQL
React, PyTorch, TensorFlow, Redux, Hugging Face Transformers, Sci-kit, Numpy, Pandas, SkLearn
Git, VS Code, MongoDB, PyCharm, Jupyter Notebook, Google Colab, Power BI
AWS, GCP, Azure DevOps, Docker, Sagemaker, Vercel, BentoML

Developed a LLM driven avatar using NVIDIA’s Omniverse platform and Audio2Face interface, integrating cutting-edge Machine Learning libraries. This solution significantly improved installation-related customer service, resulting in a 47% reduction in support ticket escalation and a 32% decrease in installation process duration. Leveraged a tech stack including Python, PyTorch, AWS, Docker, GRPC, Hugging Face, and NVIDIA Audio2Face to create a state-of-the-art avatar for enhancing customer service. Successfully delivered a robust system that demonstrated its efficiency by achieving a 92% customer satisfaction rate based on post-implementation surveys.
Developed a multi-model AI system to help the visually impaired navigate through crowded spaces. The program uses the user’s iPhone camera (ideally, this would be a set of glasses with a camera for ease of use) to scan their surroundings; sampling images every couple of seconds and passing them to the Detectron2 model. This model analyzes the image, performs object detection, and creates bounding boxes of the objects near the visually impaired individual. The bounding boxes are processed in the backend and converted into simple English descriptions (i.e. there is a chair on the left) by splitting the image into a grid with 5x5 pixel boxes. This English description is fed to Cohere’s LLM and the model provides an in-depth description of how to navigate/proceed forward. This description is fed to the individual in an audio format using Whisper from OpenAI.


Understanding why GPT's accuracy has been declining and what this means for the future of LLMs.
Read More
An article going over vision transformers and how to implement them in Python.
Read More
Understanding how neural networks can be expressed as decision trees.
Read More
Understanding how LLMs work and implementing a Language Model from scratch in Python.
Read More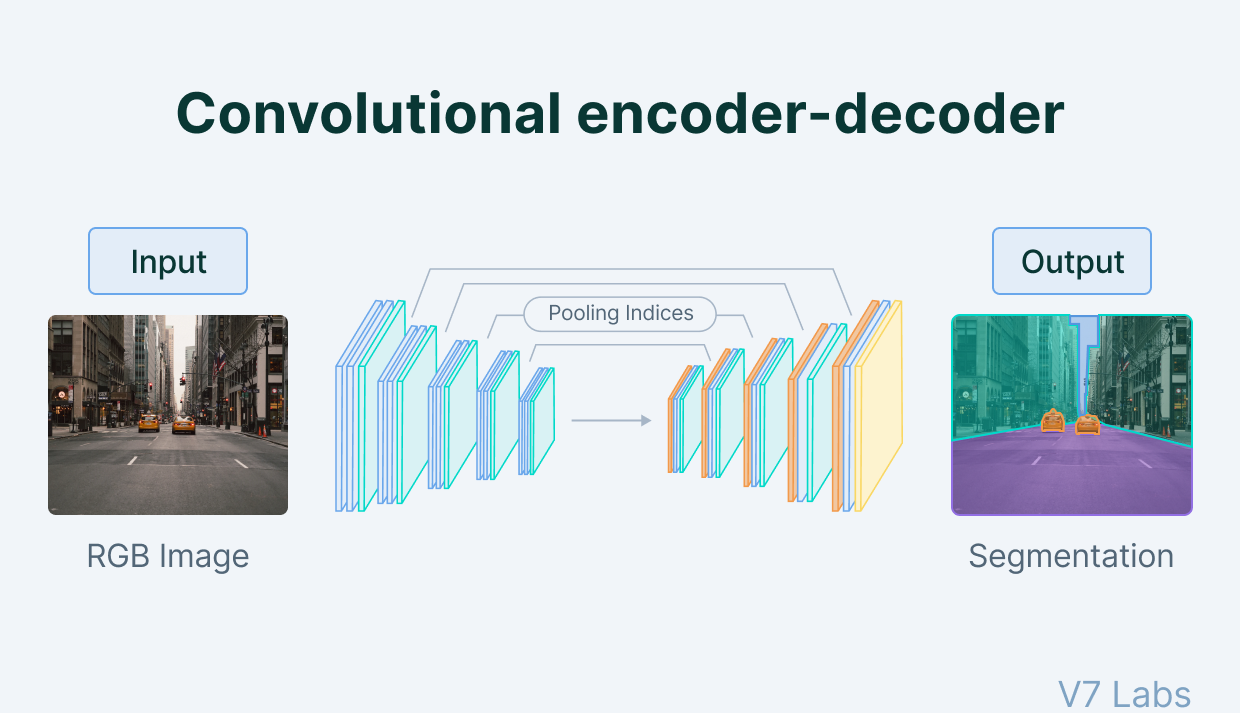
An article that goes over how to build an autoencoder from scratch & how it works.
Read More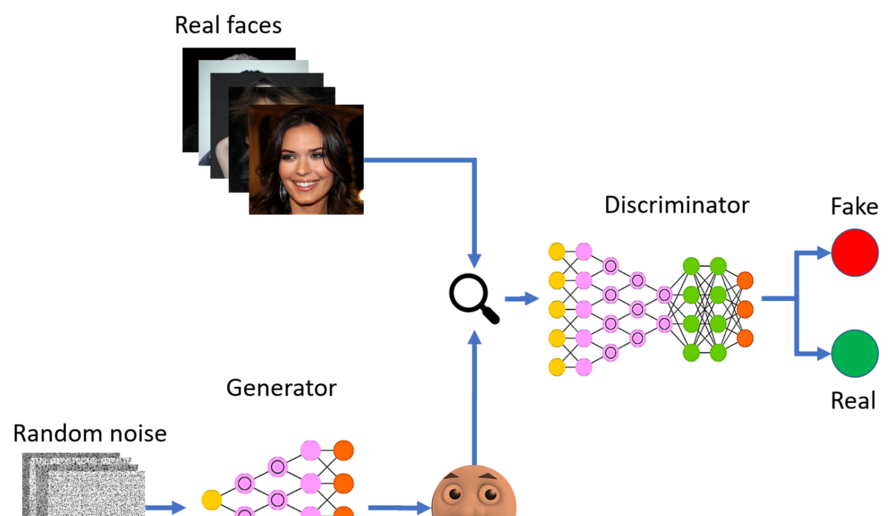
An article that goes over how to implement a GAN and understanding the theory.
Read More


Increasing IKEA's market share by adapting to the consumer of 2030.
Read More




